





XFX Radeon AI Pro
Where powerful performance meets ADVANCED AI


AMD Radeon™ AI PRO Graphics
For local AI inference, development, and other memory-intensive workloads.
Built for AI-First Professionals

Scalability and optimized performance for local inference, development, and generative AI.
Supercharge
Your Workflow

AMD Radeon™ AI PRO R9700 transforms the way you approach AI development. Cutting-edge RDNA™ 4 Architecture and 2nd-gen AI Accelerators delivers up to 2x better AI performance compared to the previous generation.¹ Equipped with 32GB of dedicated video memory, it lets you tackle larger, more complex projects without limits. Purpose-built to accelerate AI workloads locally, Radeon™ AI PRO R9700 turns your ambitions into reality with the speed and capacity your workflow demands.
Push Beyond
Desktop Limits

Unlocks lightning-fast data transfers and open a pathway to easy multi-GPU scalability with PCIe® Gen 5 support. Designed specifically for AI developers who need to run large models locally, AMD Radeon™ AI PRO R9700 eliminates cloud dependencies, handles the most memory-intensive workloads, and scales with your needs.
Optimal VRAM Buffer for Advanced Local AI

Meet the memory demands of modern LLMs and text-to-image models on your desktop with AMD Radeon™ AI PRO R9700 Graphics featuring 32GB of VRAM.
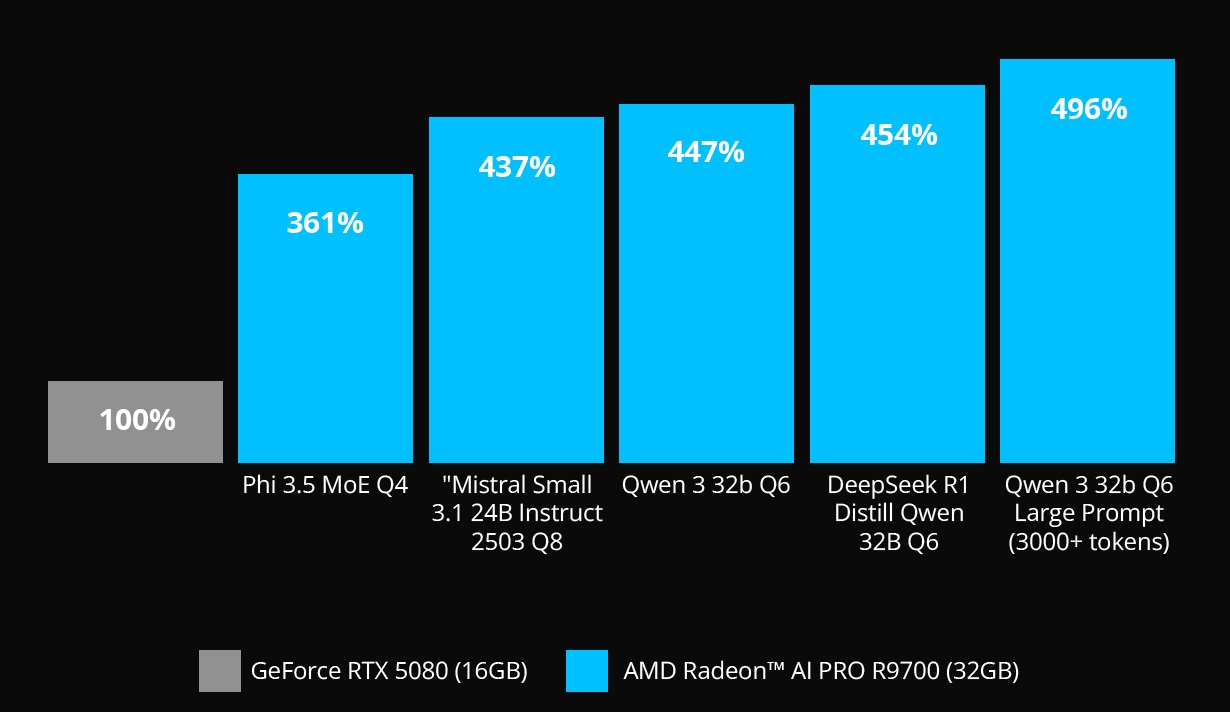
Massive Gains for Massive Models — up to 5× Faster with 32GB VRAM
AMD Radeon™ AI PRO R9700 Graphics: 32GB VRAM for Larger AI Models
Now Available at Major retailers


Get it Direct
Part Number:
RX-97XPROAIY
XFX AMD Radeon™ AI Pro R9700 32GB GDDR6 4xDP, AMD RDNA™ 4
Features:
Blower Style Cooler
2920MHz Boost Clock
RPW-495: Testing as of May 2025 by AMD. Average tokens per second of three runs, dropping edge cases where the model starts spiraling (more than 2k thinking tokens) to standardize response length. No speculative decode. All tests conducted on LM Studio 0.3.15 (Build 11). Vulkan Llama.cpp 1.28 used for AMD, NVIDIA-recommended CUDA 12 llama.cpp 1.30 with Flash Attention used for NVIDIA. Short Prompt: "How long would it take for a ball dropped from 10 meter height to hit the ground?“ Long Prompt: “Summarize the following in exactly five lines: [Insert Scene 1 Act 1 of Romeo and Juliet]”, Models tested: Phi 3.5 MoE Q4 K M, Mistral Small 3.1 24B Instruct 2503 Q8, DeepSeek R1 Distill Qwen 32B Q6, Qwen 32b Q6 System specifications: AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2, AMD Radeon™ AI PRO R9700 32GB using Adrenalin 25.6.1 RC vs AMD Ryzen™ 9 7900X, 32GB DDR5 RAM 6000 MT/s, Windows 11 PRO 24H2 with NVIDIA GeForce RTX 5080 and GeForce 576.4 drivers. Performance may vary. RPW-495.
RPW-496: Testing as of May 2025 by AMD using DeepSeek R1 Distill Qwen 32B Q6, Mistral Small 3.1 24B Instruct 2503 Q8, Flux.1 Schnell, SD 3.5 Medium models. Tested on a System with AMD Ryzen 9 7900X CPU, Radeon AI PRO R9700 GPU, 32GB DDR5 RAM, 1TB Storage, Windows 11 PRO 24H2, Adrenalin 25.6.1 RC drivers, ComfyUI - PyTorch 2.4 on Windows. System configurations may vary yielding different results. RPW-496
GD-239a: Radeon™ PRO W6000 and W7000 Series and Radeon™ AI PRO R9000 Series graphics cards (and later models) are not designed nor recommended for datacenter usage. Use in a datacenter setting may adversely affect manageability, efficiency, reliability, and/or performance.
XFX Radeon AI Pro R9600D

Get it Direct
Part Number:
RX-96XPROAIC
XFX AMD Radeon™ AI Pro R9600D 32GB GDDR6 4xDP, AMD RDNA™ 4
Features:
Passive Cooler
2020MHz Boost Clock
RAdeon AI Pro
Get it Direct
Part Number:
RX-97XPROAIY
XFX AMD Radeon™ AI Pro R9700 32GB GDDR6 4xDP, AMD RDNA™ 4
Features:
Blower Style Cooler
2920MHz Boost Clock
Get it Direct
Part Number:
RX-96XPROAIC
XFX AMD Radeon™ AI Pro R9600D 32GB GDDR6 4xDP, AMD RDNA™ 4
Features:
Passive Cooler
2020MHz Boost Clock
Get it Direct
Part Number:
RX-97XPROAIY
XFX AMD Radeon™ AI Pro R9700 32GB GDDR6 4xDP, AMD RDNA™ 4
Features:
Blower Style Cooler
2920MHz Boost Clock
